Classifying Positive Results in Clinical Psychology Using Natural Language Processing
Our paper in the Zeitschrift für Psychologie evaluates SciBERT and random forest for classifying whether clinical psychology abstracts report exclusively positive results. Trained on 1,900+ annotated abstracts, SciBERT reaches 86% accuracy and generalizes to out-of-domain data. Applied to 20,000+ psychotherapy RCT abstracts (1990–2022), the model reveals an inverted-U trend: positive results rose until the early 2010s and then declined.
📄 Paper (ZfP) | 💻 Code & Data (GitHub) | 🤗 Model (HuggingFace) | 📝 Preregistration (OSF)
Motivation: Why classify positive results?
High rates of positive results are observed throughout the sciences
Understanding trends in positive results matters for clinical psychology in particular: biased evidence on treatment efficacy can misinform clinical decisions
Previous attempts to track positive results over time relied on either manual classification—accurate but resource-intensive
We asked: Can modern NLP models learn to classify positive results from annotated abstracts, and what do they reveal about trends in clinical psychology?
Method: From annotations to transformers
Annotation strategy
We annotated 1,978 English-language abstracts from clinical psychology researchers affiliated with German universities (2013–2022). Each abstract was classified into two categories:
- Positive Results Only (PRO): All reported results support the tested hypotheses.
- Mixed or Negative Results (MNR): At least one reported result is null, negative, or hypothesis-inconsistent.
Interrater reliability was solid ($\kappa = .768$, 88% agreement on a subset of 198 independently double-coded abstracts).
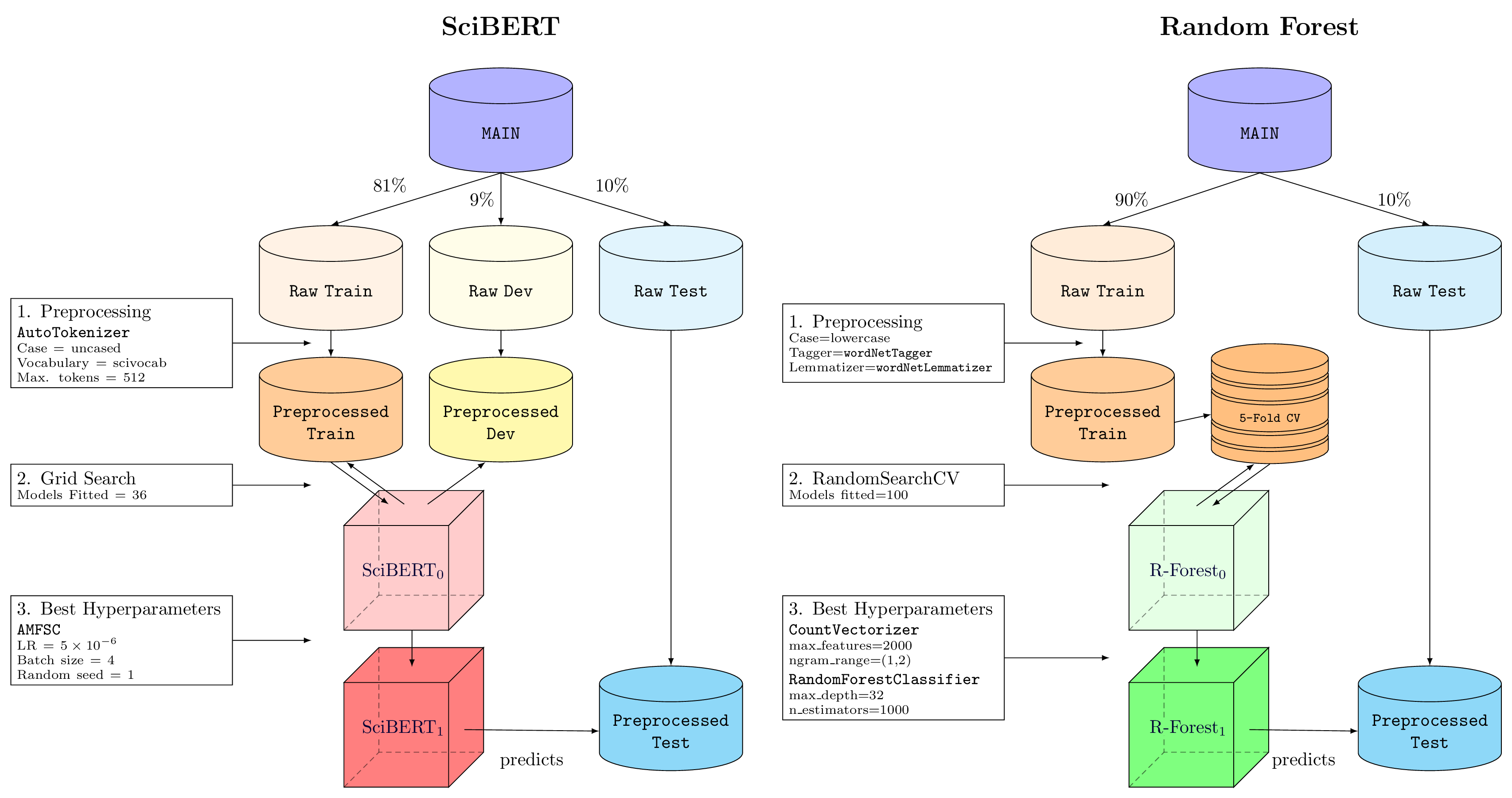
Supervised learning pipelines
We evaluated two supervised models against three benchmarks:
SciBERT
Random Forest CountVectorizer, and classified with a RandomForestClassifier
Benchmarks
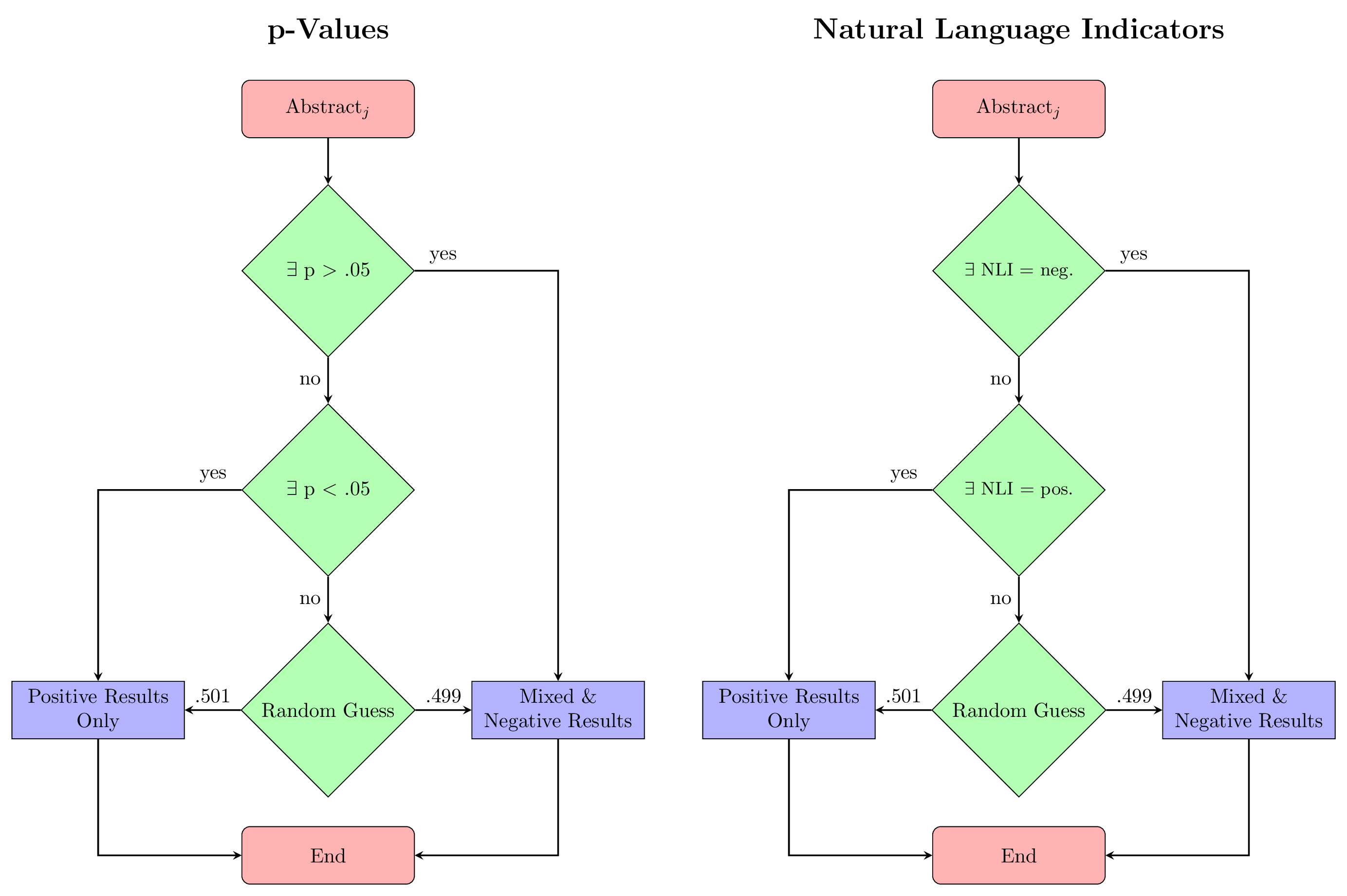
We compared against three rule-based approaches:
- p-value algorithm: Classifies based on extracted p-values (p < .05 vs. p > .05) following De Winter & Dodou
. - Natural language indicator (NLI) algorithm: Classifies based on predefined n-grams like “significant difference” or “no significant difference”
. - Naive abstract length: A logistic regression using only word count as predictor.
Results
SciBERT outperforms all benchmarks
SciBERT achieved the highest accuracy across all evaluation sets: 86% on in-domain data and 85–88% on two out-of-domain validation sets (psychotherapy RCTs from non-German authors and from 1990–2012). Random Forest showed solid but lower performance (80–83%). The rule-based benchmarks performed near chance (47–57%).
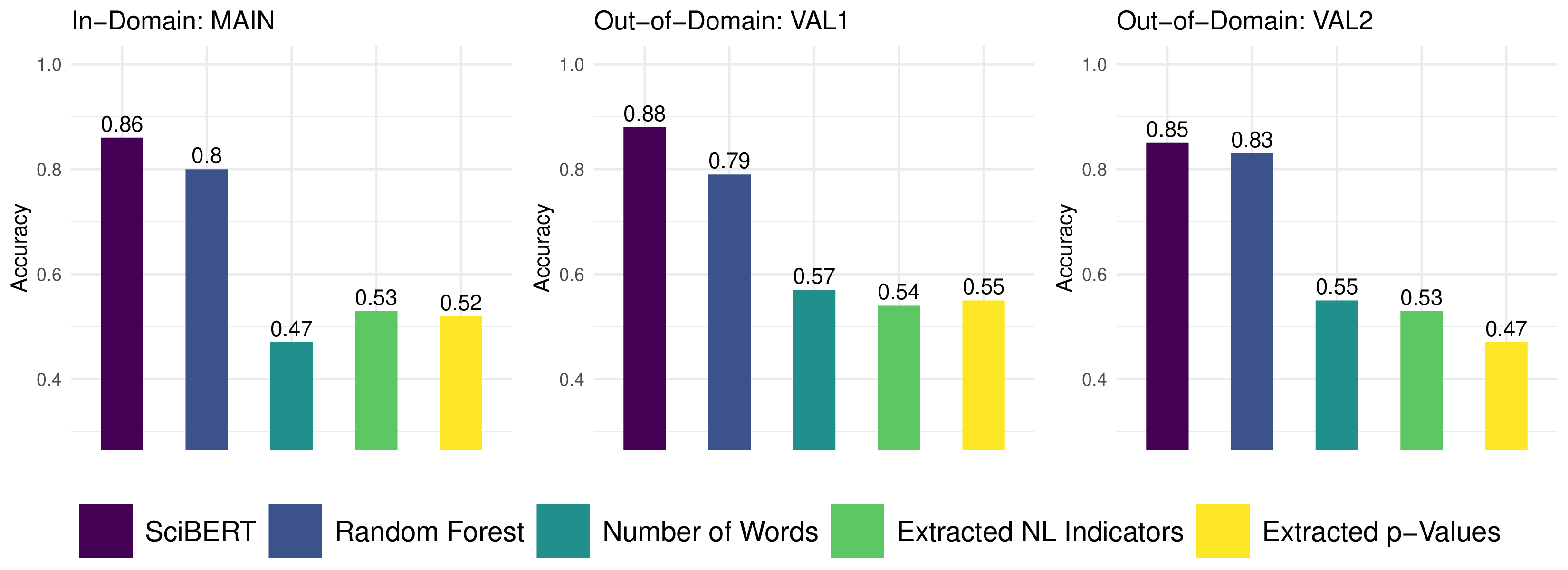
Why do rule-based approaches fail? Only 9% of abstracts in our data mentioned p-values and only 14% contained predefined NLIs, leaving 79% of abstracts where rule-based classifiers must resort to random guessing. SciBERT, by contrast, learns from the full vocabulary and linguistic context of the abstract.
The fine-tuned SciBERT model was deployed publicly as the NegativeResultDetector on HuggingFace
Trends in positive results (1990–2022)
We applied SciBERT to predict result types for 20,212 unannotated psychotherapy RCT abstracts spanning 1990–2022:
- 1990–2005: No significant linear increase in positive results ($b = 9.70 \times 10^{-3}$, $p = .191$).
- 2005–2022: A significant linear decrease in positive results ($b = -6.96 \times 10^{-3}$, $p = .034$).
- Full span (1990–2022): Significant positive linear and negative quadratic effects—an inverted-U shape. Positive results rose from the early 1990s, peaked around the early 2010s, and then declined.
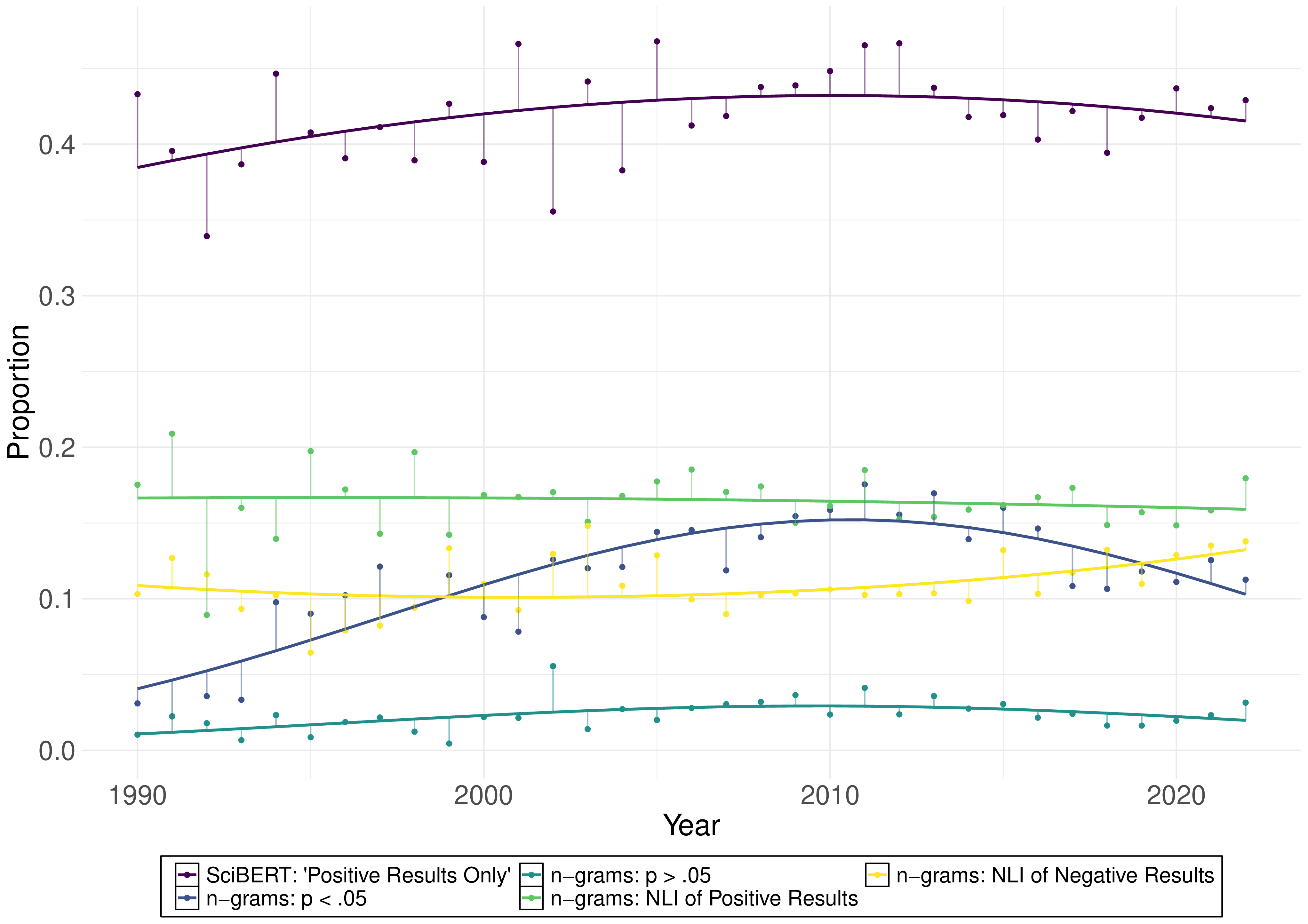
The absence of an increase in the 1990s diverges from Fanelli’s cross-disciplinary finding of rising positive results
A breakpoint analysis placed the inflection point around 2011 rather than the hypothesized 2005, suggesting a time-lag effect—research culture shifts take years to manifest in the published literature.
Discussion and implications
For metascience: Machine learning—especially transformer-based models like SciBERT—can substantially advance the automation of research synthesis tasks
For clinical psychology: The decline in exclusively positive results since the early 2010s may coincide with the adoption of open science practices such as registered reports and preregistration
Limitations: We classified abstracts (not full texts) into a binary scheme—a simplification that may obscure nuances. Larger language models with longer context windows could enable more fine-grained annotation strategies in the future. Furthermore, high rates of positive results do not necessarily imply publication bias; they could also reflect high statistical power or true effects.
Deployment: The fine-tuned SciBERT model is publicly available as the NegativeResultDetector
If you find this work useful for your research, please consider citing our paper:
@article{schiekiera2024classifying,
title={Classifying Positive Results in Clinical Psychology
Using Natural Language Processing},
author={Schiekiera, Louis and Diederichs, Jonathan
and Niemeyer, Helen},
journal={Zeitschrift f{\"u}r Psychologie},
year={2024},
doi={10.1027/2151-2604/a000563}
}
📄 Read the paper here
💻 View the code and data on GitHub
🤗 View the model on HuggingFace
📝 View the preregistration on OSF