Publication Bias in Academic Decision Making in Clinical Psychology
Our registered report in Advances in Methods and Practices in Psychological Science experimentally tests how statistical significance and hypothesis-consistency influence clinical psychologists' decisions to submit, read, and cite research. Across four within-subjects experiments with 303 researchers, we find a consistent preference for statistically significant abstracts, but no effect of hypothesis-consistency. Deliberation does not attenuate the bias.
| 📄 Paper (AMPPS) | 📝 Preregistration | 💻 GitHub |
Motivation: Why do positive results dominate?
Over 60 years ago, Sterling
Previous experimental studies produced mixed evidence—some found preferences for positive results
We address three gaps: (A) within-subjects experiments on publication bias in psychology, (B) experimental research on non-reception (reading and citing), and (C) the role of decision-making processes, drawing on Dual Process Theory

Method: Four within-subjects experiments
Experimental design and two-response paradigm
We conducted four online experiments with clinical psychology researchers ($n = 303$ total, ~75 per experiment). In each experiment, participants evaluated 16 fictitious abstracts (from 16 pairs) using a two-response paradigm:
- Stage 1 (intuitive): Fast, gut-feeling evaluation of the abstract
- Feeling of Rightness: How confident they felt about the initial response
- Stage 2 (considered): Deliberate re-evaluation with unlimited time
Experiments 1 and 2 assessed publishability (statistical significance and hypothesis-consistency, respectively). Experiments 3 and 4 assessed reading and citation likelihood.
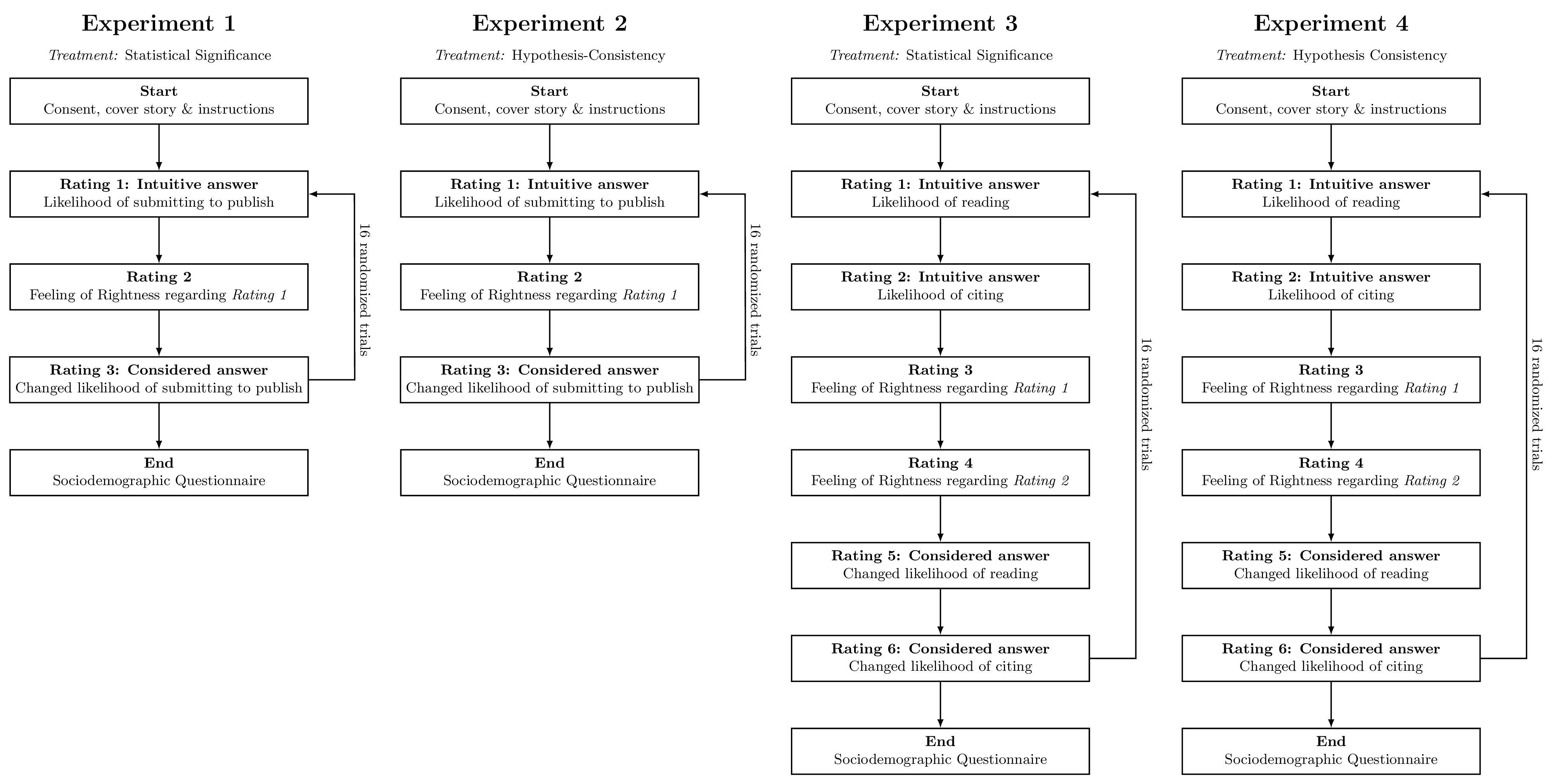
Participants and materials
We contacted 33,924 clinical psychology researchers globally; 303 completed the study (1.0% completion rate). Participants were 58% female, 40% male; 27% pre-doctoral, 29% post-doctoral, and 44% professors, from 40+ countries.
The 64 abstract pairs were carefully constructed to be identical except for the experimentally varied result section (significant vs. non-significant, or hypothesis-consistent vs. hypothesis-inconsistent). Participants were explicitly told to assume all studies had sufficient statistical power.
Results
Statistical significance reduces publishability, readability, and citability
Across all experiments involving statistical significance, non-significant abstracts were consistently rated lower:
- Publishability (Exp. 1): $b = -6.49$, $p < .001$
- Reading likelihood (Exp. 3): $b = -7.14$, $p < .001$
- Citation likelihood (Exp. 3): $b = -6.32$, $p < .001$
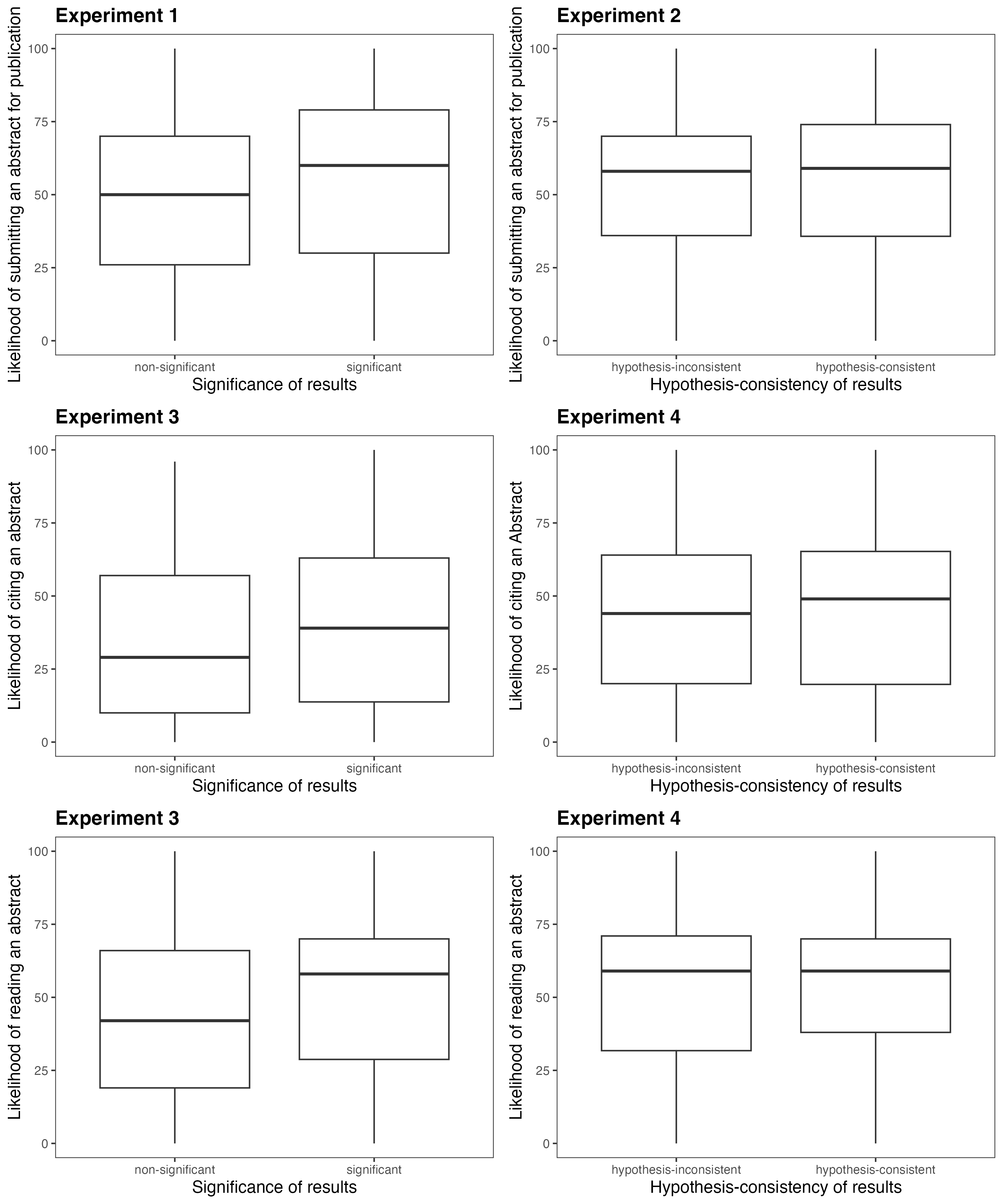
Hypothesis-consistency has no effect
Whether an abstract’s results were consistent or inconsistent with its hypothesis had no detectable effect on any outcome:
- Publishability (Exp. 2): $b = -1.21$, $p = .303$
- Reading (Exp. 4): $b = -1.29$, $p = .281$
- Citation (Exp. 4): $b = -1.44$, $p = .222$
Deliberation and Feeling of Rightness
In most experiments, initial intuitive evaluations were not revised after deliberation. FOR did not systematically mediate response changes. One exception: in Experiment 1, non-significant abstracts lowered FOR ($b = -0.16$, $p = .006$), but higher FOR unexpectedly predicted more positive revision—contrary to our hypothesis.
Discussion and implications
For metascience: Our within-subjects design provides experimental evidence that statistical significance—but not hypothesis-consistency—is associated with researchers’ evaluations of abstracts for publication, reading, and citation. Effect sizes were small (1–2% of variance), reflecting the multifactorial nature of these decisions, but the pattern was consistent across four experiments.
For decision-making research: The two-response paradigm revealed that deliberation does not attenuate the significance bias. This suggests that the preference for significant results operates as a persistent heuristic rather than a correctable first impression.
For clinical psychology: If non-significant findings are less likely to be read and cited
Limitations: This is a controlled vignette study; how strongly these patterns translate into real-world publication outcomes with actual manuscripts and real incentives remains to be tested in field experiments.
If you find this work useful for your research, please consider citing our paper:
@article{schiekiera2025publication,
title={Publication Bias in Academic Decision Making
in Clinical Psychology},
author={Schiekiera, Louis and Eichel, Kristina and Sachse,
Jacqueline and M{\"u}ller, Sophie P. and He{\ss}elmann,
Felicitas and Niemeyer, Helen},
journal={Advances in Methods and Practices in Psychological Science},
year={2025}
}
📄 Read the paper here: https://doi.org/10.1177/25152459251338393
📝 View the preregistration on OSF: https://osf.io/6tpm7
💻 View the code on GitHub: https://github.com/schiekiera/metascience_experiment_history